Compound Components: Truly Flexible React APIs
Build flexible, declarative UIs like native HTML with Compound Components—a powerful React pattern you’ll master at EpicReact.dev.

Kent C. Dodds
React Suspense for Data Fetching is an experimental feature in React that opens the doors to a lot of really awesome performance improvements as well as developer experience improvements thanks to the declarative APIs given around asynchrony.
A read-through of the docs is suggested because it's interesting. One of the things that I find of particular interest in the docs is the section titled "Approach 3: Render-as-You-Fetch (using Suspense)." The arguments for this approach is the performance improvement opportunity which I tried to sum up in this tweet:
https://twitter.com/kentcdodds/status/1191922859762843649
To boil it down, we're talking about what happens when the user performs an action that results in loading some code that's been code-split (like navigating to a route).
So, here's the user interaction we're going to use for our example:
So here's what most of us do (no shame, it's just natural):
Here's what that might look like in the network tab:
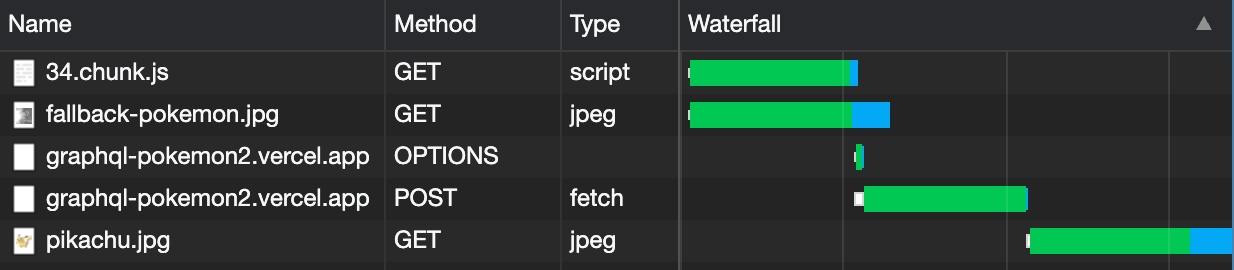
This is what we call a "waterfall" effect. Because the lazily-loaded code is the code that requests the data, we have to wait until it's loaded before we can actually request the data and assets it needs.
In project management terms, this waterfall effect is what we call the "critical path":
In project management, a critical path is the sequence of project network > activities which add up to the longest overall duration, regardless if that > longest duration has float or not. This determines the shortest time possible > to complete the project. There can be 'total float' (unused time) within the > critical path. – > Wikipedia
But here's the important aspect of the critical path: it's all about dependencies. And successful project managers know how to reduce dependencies so we can take advantage of parallization and hopefully reduce the time it takes to complete the project.
So, in our case, what if there's a way for us to start loading the data and assets as well as the code all at the same time? Would that not speed things up? You bet it would! Check this out:
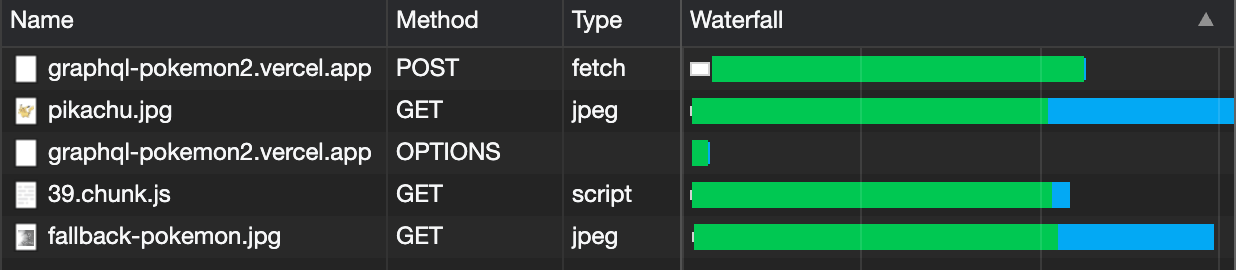
Because we already have all the information we need to start pre-loading the code, data, and assets, we simply fire off those requests all at the same time.
But this begs the question: "Why do we have those dependencies in the first place? Why don't we always trigger these requests right away?" The answer is because it's easier to maintain code where the data requirements are colocated with the code that requires the data.
But in EpicReact.Dev, you'll learn how you can get the benefits of data colocation as well as pre-loading of code, data, and assets and how to do that both with "suspense for data fetching" as well as without.
Delivered straight to your inbox.
Build flexible, declarative UIs like native HTML with Compound Components—a powerful React pattern you’ll master at EpicReact.dev.
Whether you're brand new to building dynamic web applications or you've been working with React for a long time, let's contextualize the most widely used UI framework in the world: React.
A deep dive into how React error boundaries work, why they're different from try/catch, and how to use them effectively in your apps.
If you use a ref in your effect callback, shouldn't it be included in the dependencies? Why refs are a special exception to the rule!